Axional Analytics
Cada día las empresas crean enormes cantidades de datos relacionados con sus operaciones. Sin embargo, aun con todos estos datos, disponen de poca información. Axional Analytics está diseñado para convertir los datos en información útil al permitir la agregación de datos, proporcionando así a los usuarios la información que necesitan para tomar decisiones eficaces sobre la orientación estratégica de su organización.
El Axional Analytics suite consta de dos herramientas: una de Data Warehouse y una del análisis OLAP para los usuarios finales. Mediante la combinación de estas herramientas, Axional Analytics es capaz de manejar grandes cantidades de datos procedentes de múltiples fuentes. Esta perspectiva les proporciona a los gerentes una visión global, utilizada para tomar decisiones oportunas.
Con Data Warehouse, las empresas serán capaces de contestar preguntas que empiecen por “quién” y “qué”. El módulo OLAP constituye el siguiente paso, ya que posibilita las respuestas a preguntas que empiecen por “qué pasaría si…” y “por qué”, las cuales mejoran la toma de decisiones acerca de futuras acciones. Eso, por lo general, es un proceso más complejo que la simple recolección de datos.
Aplique Business Intelligence sobre los datos de su empresa
El proceso ETL
A los usuarios les encantan las herramientas de Business Intelligence. Les proporcionan varios gráficos, objetivos, desgloses, y analísis drill down y drill across. Sin embargo, en un entorno analítico, la obtención de datos de sistemas operativos en Data Warehouse forma gran parte del trabajo. Este proceso permite que las herramientas de BI nos muestren dichas visualizaciones.
El módulo de ETL es una plataforma de integración de datos empresariales, notablemente fácil de escalar. Posee capacidades extraordinarias en cuanto a la extracción, transformación, y carga (ETL). El módulo se basa en un motor de transformación de datos. Se opera a un nivel de abstracción más alto que muchas herramientas de desarrollo visual. Como regla general, los desarrolladores pueden lograr mucho más con este motor que con 3GLs, y con un menor número de sentencias. Esta diferencia se debe a los siguientes factores:
- Programación sencilla: basado en el lenguaje de scripting XSQL, nos permite definir los complejos procesos de ETL claramente.
- Potencia: se ha incorporado un amplio conjunto de funciones. Dispone de más de 300 funciones y conectores predefinidos para múltiples bases de datos y formatos de archivo. Esta flexibilidad permite la definición de complejos flujos de control, flujos de datos, lógica orientada a eventos y registros.
Este módulo consolida los datos de varios sistemas de origen, con distintos formatos u ordenaciones de datos. Se diseñó específicamente para trasladar grandes volúmenes de datos y aplicar reglas de negocio complejas, para juntar todos los datos de la empresa en un ambiente estandarizado y homogéneo. Las características principales de esta herramienta son:
- Las funciones de lectura/escritura poseen acceso a la mayoría de las fuentes de datos.
- Las fuentes de datos están consolidadas en un warehouse de datos central, también denominado un data mart.
- Se proporcionan varios indicadores cualitativos y cuantitativos para optimizar el trabajo.
- El soporte de Unicode provee el conjunto completo de caracteres internacionales, sin importar dónde se haya realizado el trabajo. Se puede recoger y almacenar datos que provengan de todo el mundo.
- Las funciones definidas por el usuario se ejecutarán durante del proceso ETL.
- La captura de datos modificados es continua. Se identifica y captura toda la información que se ha añadido o actualizado.
El lenguaje XSQL permite la definición de reglas complejas para transformar los datos primarios. A continuación hay algunos ejemplos:
- La validación de datos. Se incluye la validación por la intersección entre varias columnas.
- La codificación de valores de forma libre (por ejemplo, el mapeo de textos sobre códigos).
- La derivación de nuevos valores calculados.
- La anonimización de valores para cumplir con los requisitos de privacidad de datos.
- La transposición de columnas y filas.
- Las funciones de agregación.
Como paso final, la información se carga en el destino, que por lo general consta de un Data Warehouse o datamart. Las actualizaciones pueden realizarse mediante la sustitución de los datos anteriores, la actualización de los datos existentes, o la adición de información acumulada.
La herramienta nos proporciona conectores para la extracción a partir de múltiples fuentes de datos, desde texto sencillo a bases de datos, Excel, XML, y otros.
La fuente de la información se extrae por el streaming de datos. Se la puede cargar inmediatamente en la base de datos destinataria, sin la necesidad de almacenar los datos como paso intermedio. Las funciones de carga avanzadas permiten, en la mayoría de los casos, que se integren todas las fases de ETL en un solo proceso, así aumentando la seguridad y la fiabilidad.
Una parte intrínseca de la extracción consta del análisis de los datos extraídos, comprobando que la información posee el patrón esperado o la estructura esperada. En caso contrario, es posible que se rechace la información, sea parcialmente o completamente.
- Las fuentes de datos relacionales: Incluyen los conectores de JDBC / ODBC para las bases de datos como IBM Informix, IBM DB2, Oracle, SQL Server, MySQL o Postgres. Las consultas definidas por XML permiten la definición de relaciones y la recuperación de datos desde múltiples tablas.
- Las fuentes de datos no relacionales: La recuperación directa en Excel nos proporciona soporte para los rangos de múltiples hojas y rangos nombrados. El texto está codificado y es multilingüe, con cargadores nativos al CSV, Fixed Width, o RegEx cuando se requiere una operación de extracción de texto avanzada. El soporte de XQuery / XPath para la extracción de XML está disponible.
- Las fuentes de datos auxiliares: Se crean fuentes de datos en memoria para los pequeños conjuntos de datos, como por ejemplo una tabla de códigos o propiedades traducidas. Éste constituye un método seguro para la transmisión de datos cifrados.
- Se extraen los atributos de archivo de un sistema de archivos, y los coloca en una carpeta para que se los procesen como registros regulares.
- El acceso a los datos, incluyendo datos de tipo XML y textual, ocurre a través de HTTP / HTTPS, TCP, y FTP / FTPS.
- Existen varios métodos para descomprimir los archivos de origen: zip, compresión, gzip, b2zip, etc. También existen métodos para extraer datos de los archivos, y para manipular los archivos y directorios.
La etapa de transformación aplica una serie de reglas o funciones a los datos extraídos de la fuente, con la finalidad de obtener los datos finales y cargarlos en la base de datos destinataria. Esta herramienta proporciona la capacidad de:
Comprobar los datos contra cientos o incluso miles de reglas de negocio, sin limitaciones del rendimiento.
Registrar errores, rechazar registros, y controlar el flujo de ejecución.
Utilizar un amplio conjunto de funciones para transformar los datos, así posibilitando:
- La traducción de valores codificados (por ejemplo, si el sistema almacena ‘1’ para ‘encendido’ y ‘2’ para ‘apagado’, pero el almacén utiliza ‘O’ para ‘encendido’ y ‘F’ para ‘apagado’).
- La derivación de nuevos valores calculados (por ejemplo, importe_ventas = cantidad * precio_unidad – valor_descuento).
- Las operaciones de búsqueda y la validación de datos relevantes provenientes de tablas o archivos de referencia. Esto permite el cambio gradual de las dimensiones.
- La anonimización, con soporte para los algoritmos de hashing de MD5 y Whirlpool.
- La validación de datos simples o complejos. Si la validación falla, un rechazo de los datos total, parcial o nulo puede resultar.
- La generación de valores de claves sustitutas.
Carga y anonimización de datos en un solo paso: la anonimización y la normalización se realizan durante la carga de datos externos desde los archivos. Para cada línea del archivo fuente, se ejecutan los siguientes pasos:
- Leer la línea en la memoria.
- Ejecutar operaciones de filtrado en memoria, permitiendo la anonimización y la normalización. El uso de funciones definidas localmente como filtros permite procedimientos de anonimización personalizados.
- Carga los datos resultantes en la tabla.
La etapa de carga (“Load”) tiene como resultado el almacenamiento de los datos en el sitio destinatario, típicamente el almacén de datos (data warehouse) or una base de datos de pruebas (área de stage).
La inserción de los nuevos registros y la actualización de los existentes se realizan mediante una búsqueda de las columnas de clave primaria. Si los datos cargados contienen una clave primaria (PK) de un registro existente, el registro se actualiza. Por otro lado, si el registro ya está actualizado y la PK es nueva, se inserta el registro. Para el rendimiento optimizado, se pueden definir dos distintos algoritmos de actualización, según el tipo de datos. En el caso de las tablas de hechos, se intenta una operación de inserción primero, y si la PK existe, la actualización se realiza. En el caso de las tablas maestras, la primera operación que se intenta es de actualización, y si ningunos registros están actualizados, entonces se realiza la inserción.
El sistema asimismo provee la capacidad de gestionar datos históricos. En este caso, se archivan todos los cambios a los registros, así posibilitando la reproducción de todas las versiones anteriores de los informes.
Los sistemas destinatarios podrían constar de una base de datos conectada mediante JDBC, un archivo, o incluso datos transmitidos subidos a HTTP, FTP o TCP.
La integración con Informix IWA: tras cargar datos en la base de datos destinataria de Informix, el proceso ETL puede, de forma automática, iniciar el proceso para la actualización de los datos del Warehouse Accelerator Datamart.
Esta herramienta permite el procesamiento paralelo masivo (MPP) para grandes volúmenes de datos. Las empresas deberían tener en cuenta que la simplicidad forma una parte esencial del rendimiento. Por lo tanto, el método de “extraer, aplicar funciones de transformación y cargar” es el algoritmo más rápido y sencillo para los procesos de ETL, ya que supone solo un paso.
En nuestros sistemas de pruebas, se puede extraer un archivo con un millón de registros, además de anonimizarlo mediante los métodos de WHIRLPOOL, normalizarlo, y cargarlo en una tabla de base de datos. Estos pasos se pueden realizar en menos de 8 minutos, sin el uso de la paralelización.
El proceso ETL
La finalidad del motor de OLAP es poder responder a las consultas de los usuarios del cubo. Las consultas de OLAP se realizan en el lado del servidor, con la interfaz de Java. Para mejorar el rendimiento, el motor de Axional ROLAP puede funcionar en ordenadores de servidor especialmente configurados.
Junto con su arquitectura específica, el motor de Axional OLAP incluye los siguientes beneficios:
La minimización de la cantidad de datos trasladados entre el RDBMS y la aplicación cliente, mediante:
- El almacenaje (en tablas temporales, tablas derivadas…) de resultados de consultas intermediarias de SQL multi-paso, además de su agrupación en el RDBMS.
- El traslado de todos los cálculos al RDBMS.
- El traslado de todos los filtros y todas las agrupaciones al RDBMS.
- El traslado de todos los filtros y todas las agrupaciones aplicados a los cálculos al RDBMS.
La optimización de SQL en función del tipo del RDBMS.
El soporte para el SQL multi-paso, lo cual es un requisito para responder a preguntas analíticas que un solo paso de SQL no pudiera resolver.
La gestión eficiente de modelos de datos normalizados o no normalizados.
La resolución automática de errores y conflictos típicos para las consultas de start o Snowflake.
El módulo Axional OLAP utiliza una visión multidimensional de los datos agregados para proporcionar acceso rápido a la información estratégica para su posterior análisis. Los usuarios obtienen más perspectivas sobre los datos a través del acceso rápido, consistente, e interactivo. Se provee una amplia variedad de posibles puntos de vista sobre la información. Este hecho permite que todos los responsables de la organización puedan ver el data warehouse de la empresa desde su punto de vista particular.
Este módulo también les proporciona a los usuarios la información necesaria para tomar decisiones eficaces sobre la orientación estratégica de la empresa. Sus características incluyen tanto la navegación básica como los cálculos complejos y el análisis profundo, como por ejemplo las series temporales. Los que toman las decisiones adquieren experiencia con las capacidades del OLAP, y van más allá del acceso a los datos, llegando al conocimiento verdadero.
La finalidad de esta herramienta es convertir sus datos empresariales en verdadero BI. Para lograr este objetivo, se utiliza una estructura de datos pre-configurada, tipo datamart, que simultáneamente ofrece una configuración flexible.
El módulo Axional OLAP separa a los usuarios de la compleja sintaxis de consultas, diseños de modelos y joins de SQL. Su visión multidimensional de los datos proporciona una base para el procesamiento analítico, a través del acceso flexible a la información. Los usuarios se ven capaces de analizar los datos a través de cualquier dimensión, a varios niveles de agregación, con tanta funcionalidad como facilidad.
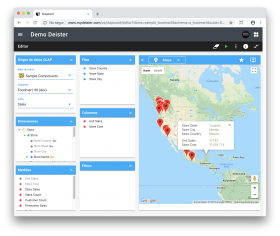
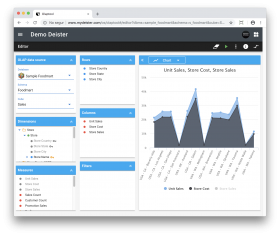
El módulo OLAP opera en función de los hechos, y los hechos se pueden desglosar como números. Un hecho podría ser un recuento de ventas, la suma de los importes de ventas, o un promedio. Los hechos también se denominan Medidas, y éstas se organizan en Dimensiones, las formas en las que se puede desglosar los hechos. Por ejemplo, se podría dividir las ventas totales por la región geográfica. Del mismo modo, las ventas totales también podrían desglosarse por el tiempo. Las dimensiones también contienen jerarquías de niveles.
El conjunto de las dimensiones y medidas se llama un Cubo. Los cubos facilitan el análisis multidimensional de datos, respondiendo a preguntas de negocio complejas. El hecho de que puedan constar de más de tres dimensiones (hipercubo) habilita el análisis profundo, lo cual permite que los usuarios obtengan una visión completa y útil del negocio.
Axional Analytics permite un número prácticamente ilimitado de dimensiones añadidas a la estructura de datos (el cubo OLAP), lo cual permite el análisis de datos detallado. Los analistas pueden visualizar conjuntos de datos desde distintos ángulos o pivotes.
Se utiliza una base de datos relacional, la cual almacena de forma directa la información contenida en los varios cubos (el modelo OLAP). Este enfoque traduce las consultas nativas al OLAP, convirtiéndolas en sentencias de SQL adecuadas. Gracias al uso de potentes y eficaces herramientas de bases de datos, tales como el Informix IWA, el rendimiento de este enfoque es equivalente al rendimiento de una base de datos MOLAP.
Este enfoque también permite la implementación sencilla de la analítica en memoria, y como resultado el análisis es más rápido, con una mínima necesidad de utilizar la TI. La analítica en memoria elimina la necesidad de almacenar los datos pre-calculados en forma de cubo OLAP o tabla agregada. A los usuarios empresariales les ofrece conocimientos adquiridos más rápidamente, además del acceso al análisis de grandes conjuntos de datos, con mínimos requisitos de gestión de datos.
Mediante el proceso de ETL, se puede crear varios cubos, cada uno con un conjunto específico de dimensiones ajustadas a los requisitos de un determinado grupo de usuarios. Mediante los cubos, los gerentes ganan conocimientos acerca de sus datos a través de métodos rápidos, precisos, y flexibles. Asimismo adquieren varias vistas de sus métricas de negocio, las cuales transforman los datos primarios en información significativa.
La optimización de Axional Analytics para el IBM IWA
En el ámbito analítico, las consultas pueden constituir una causa notable de la pérdida de tiempo. El tiempo perdido en espera de respuestas también constituye una pérdida de productividad. A medida que las empresas acumulan cada vez más datos, incluso las consultas básicas pueden tardar considerablemente. Por lo tanto, Axional Analytics está plenamente integrado con el IBM Warehouse Accelerator (IWA), la primera base de datos columnar y en memoria. Es capaz de procesar cantidades masivas de datos en cuestión de segundos.
IBM Warehouse Accelerator se considera un sistema ideal para la implementación de almacenes de datos. Nos proporciona un rendimiento extremadamente alto, a la vez que elimina la mayoría de los ajustes necesarios en los sistemas tradicionales de data warehouse.
El acelerador de IBM ofrece una gama de características claves e impresionantes:
- Provee la aceleración sin la necesidad de realizar ajustes manuales para cada trabajo. No hace falta crear ni reorganizar un índice. Tampoco hay estadísticas para recoger, ni particiones para crear, ni ajuste, ni gestión del almacenamiento.
- No son necesarias las tablas de resumen ni las vistas materializadas. Los usuarios pueden aprovechar directamente de las tablas de hechos.
- Se escanean miles de millones de filas en cuestión de segundos. La profunda representación columnar de datos, además del procesamiento de consultas de datos comprimidos, anula la necesidad de hacer ajustes.
- El rendimiento lineal: el rendimiento de las consultas depende del volumen de datos, y no de la complejidad de la consulta.
Axional Analytics también nos ofrece algunas características claves para mejorar la integración con el sistema de almacenes Informix:
- Las instantáneas automáticas de los datos actualizados de ETL para Warehouse Accelerator
- La optimización de las sentencias SQL para asegurar la compatibilidad con el IWA
- La generación de avisos si se producen consultas con tablas o columnas que no estén presentes en el datamart
Herramientas del cliente
Hay dos distintos clientes de OLAP que proporcionan una sencilla interfaz de usuario. Ésta automáticamente recupera y formatea los datos en función de las definiciones de modelos existentes, para cada consulta realizada por el usuario:
- Agrupación
- Profundización (drill down): Navegar a un nivel más detallado del cubo.
- Agregación (drill up): Navegar a un nivel más resumido del cubo.
- Ordenar, introducir, y explorar datos de forma dinámica.
- Vistas de gráficos y visualizaciones.
- Exportación de los datos a Excel.
- Operaciones avanzadas de ordenación y filtrado.
Potencia tu empresa hoy
Nuestro equipo está listo para ofrecerte los mejores servicios